TrimAll
지정된 공백이 제거되거나 삽입된 텍스트의 사본을 반환합니다.
포맷
TrimAll(텍스트 ; 자르기 공간 ; 자르기 유형)
매개 변수
텍스트 - 임의의 텍스트 표현식 또는 텍스트 필드
자르기 공간 - 0 또는 False, 1 또는 True
자르기 유형 - 사용할 자르기 스타일에 따라 0~3
반환되는 데이터 유형
텍스트
다음 버전에서 시작됨
6.0 또는 이전
설명
TrimAll을 사용하여 텍스트와 로마체가 아닌 공백(전각 및 반각 공백과 같은)으로 작업할 수 있습니다. 로마체 공백의 경우 Trim 함수를 사용합니다.
전각 공백을 제거하려는 경우 자르기 공간을 True(1)로 설정합니다. 전각 공백을 유지하려는 경우 자르기 공간을 False(0)로 설정합니다.
유니코드 값이 U+2F00 미만인 경우 문자는 로마체로 간주됩니다. 유니코드 값이 U+2F00 이상인 문자는 로마체가 아닌 문자로 간주됩니다.
로마체 범위 내의 문자는 다음 문자 블록에 속합니다. Latin, Latin-1 Supplement, Latin Extended-A & B, IPA Extensions, Spacing Modifier Letters, Combining Diacritical Marks, Greek, Cyrillic, Armenian, Hebrew, Arabic, Devanagari, Bengali, Gurmukhi, Gujarati, Oriya, Tamil, Telugu, Kannada, Malayalam, Thai, Lao, Tibetan, Georgian, Hangul Jamo 및 추가 Latin 및 Greek 확장 블록.
로마체 범위 내의 기호는 문장 부호, 위 첨자, 아래 첨자, 통화 기호, 기호의 통합 기호, 문자 모양 기호, 숫자 형식, 화살표, 산술 연산자, 제어문자 표시, 기하학적 모양, 장식 문자 등이 있습니다.
로마체가 아닌 범위 내의 문자는 한중일 기호 및 문장 부호 영역, 히라가나, 가타카나, 주음 부호, 한글 호환 자모, Kanbun, 한중일 통합 한자 등이 있습니다.
다음 테이블에서 제공된 경우 공백이 자르기 유형 값에 따라 제거되거나 삽입됩니다.
|
|
방법 |
|
0 |
로마체가 아닌 문자와 로마체 문자 사이의 모든 공백을 제거합니다(로마체 단어 사이에 항상 공백 하나를 남김). |
|
1 |
로마체가 아닌 문자와 로마체 문자 사이의 반각 공백을 항상 포함합니다(로마체 단어 사이에 항상 공백 하나를 남김). |
|
2 |
로마체가 아닌 문자 사이의 공백을 제거합니다(로마체가 아닌 문자와 로마체 단어 사이에 여러 공백을 줄임. 아무 것도 없는 경우 공백을 추가하지 않음. 로마체 단어 사이에 항상 공백 하나를 남김). |
|
3 |
모든 곳의 모든 공백을 제거합니다. |
모든 경우에 로마체가 아닌 문자 사이의 공백이 제거됩니다.
|
유형 |
비 로마체 - 비 로마체 |
비 로마체 - 로마체 |
로마체 - 로마체 |
|
0 |
제거 |
제거 |
공백 1개 |
|
1 |
제거 |
공백 1개* |
공백 1개 |
|
2 |
제거 |
공백 1개 |
공백 1개 |
|
3 |
제거 |
제거 |
제거 |
* = 공백이 없는 경우 로마체가 아닌 문자와 로마체 사이에 공백을 삽입합니다.
참고
- 전각 공백은 일본어와 같이 일부 로마체가 아닌 언어에만 표시됩니다. 로마체 언어만 사용하는 경우
자르기 공간을 False(0)로 설정합니다.
예제 1
TrimAll(" Julian Scott Dunn ";0;0)은 Julian Scott Dunn을 반환합니다.
예제 2
TrimAll( )는
)는  필드의 값이
필드의 값이 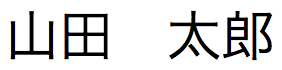 인 경우
인 경우  를 반환합니다.
를 반환합니다.
예제 3
TrimAll(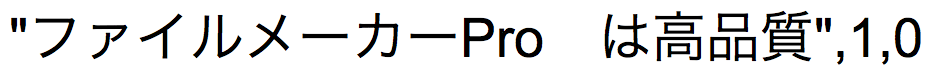 )은
)은 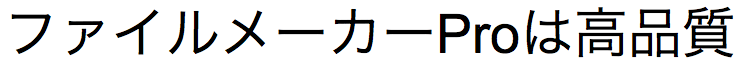 을 반환합니다.
을 반환합니다.