検索対象 | 検索フィールドに入力するデータ | 例 |
特定の文字で始まる単語 (日本語以外の言語を使用するフィールドが対象) | 検索する文字 | "Chris Smith"と入力すると、「Chris Smith」、「Smith Chris」、「Chris Smithson」、および「Smith Christenson」が検索されます。 |
特定の文字で始まる単語 (日本語のフィールド) | 検索する文字を = と * の間に入力します。 | |
特定の文字列 | スペースや句読点を含む文字をダブルクォーテーションマーク (") で囲んで入力します。 | ""株式会社 平成堂""と入力すると、「株式会社 平成堂」は検索されますが、「平成堂 株式会社」は検索されません。 "",Ltd."" は、名前に「,Ltd.」がつく会社すべてを検索しますが、コンマ無しの社名は検索されません。 "Spring" と入力すると、「Springville」は検索されますが、「ColdSpring Harbor」や「HotSpring」は検索されません。 |
1 文字以上の任意の文字を含む文字列 | どの文字が挿入されても構わない位置にワイルドカード文字 (@) を 1 文字に 1 つずつ入力します。 | "小@川"と入力すると、「小田川」や「小野川」が検索されます。 "@on"と入力すると、「Don」と「Ron」は検索されますが、「Bron」は検索されません。 |
テキストフィールドで無効な文字 | ?
| 無効な文字は空白文字として表示されます。 メモ ? 文字を検索するには、""?""を検索します。 |
テキストフィールドの数字 (任意の桁) | それぞれの数字に # 文字を入力します。 | "#"と入力すると、「3」は検索されますが、「30」は検索されません。 "##"と入力すると、「30」は検索されますが、「3」や「300」は検索されません。 "#3"と入力すると、「53」や「43」は検索されますが、「3」は検索されません。 |
0 文字以上の任意の文字列を含む文字列 | どのような文字が挿入されても構わない位置にワイルドカード文字 (*) を入力します。 | "小*川"と入力すると、「小川」、「小田川」、「小野川」など検索されます。 "J*r"と入力すると、「Jr.」や「Junior」などが検索されます。 "*川一*"と入力すると、「小川一郎」や「小野川一明」などが検索されます。 "S*"と入力すると、「Sophie」、「Steve」、および「Sven」が検索されます。 |
句読点やスペースなどを含む演算子または英数字以外の文字 | スペースや句読点を含む文字をダブルクォーテーションマーク (") で囲んで入力します。 | ""@""と入力すると、「@」(または電子メールアドレスなど) が検索されます。 "",""と入力すると、コンマを含むレコードが検索されます。 "" ""と入力すると、スペースが 3 つ並んでいるデータが検索されます。 |
表示されない文字や FileMaker Pro Advanced で認識される検索演算子など、特別な意味を持つ文字: @、*、#、?、!、=、<、>、" (次の文字をエスケープ) | 検索する特殊文字の前に \ 記号を入力します。 改行の場合、ブラウズモードでフィールドに改行を入力してクリップボードにコピーします。次に検索モードで\ を入力し、改行を貼り付けます。 タブの場合、\ を入力して Ctrl+Tab (Windows) または option-tab (macOS) を押します。 | "\"小田\""と入力すると、「"小田"」が検索されます。 "joey\@abc.net"と入力すると、電子メールアドレス「joey@abc.net」が検索されます。 "\
小田"と入力すると、小田の前に改行が付いて検索されます。
|
アクセント記号付きの単語 | スペースや句読点を含む文字をダブルクォーテーションマーク (") で囲んで入力します。 | ""òpera""と入力すると、「òpera」は検索されますが、「opera」は検索されません。 ダブルクォーテーションマークで囲まずに"òpera"と入力すると、「òpera」と「opera」の両方が検索されます。 |
特定の文字列 (単語の一部など) を含む文字列 | 文字、句読点、スペースをダブルクォーテーションマーク (") で囲んで入力します。どのような文字がきても構わない部分に"*"を入力します。 | "*"山県の名産""と入力すると、 「和歌山県の名産」や「岡山県の名産」などが検索されます。 |
指定したテキストに完全に一致するレコード | 検索する各文字列の前に == (2 つの等号記号) を付けて文字列を入力します。 | たとえば、「名前」フィールドに「鈴木 理香」、「鈴木 リカ」、「鈴木」が含まれていた場合、"==鈴木"と入力すると、「鈴木」だけが検索され、「鈴木理香」と「鈴木リカ」は検索されません。 "==鈴木リカ"と入力すると、「鈴木 リカ」だけが検索され、「鈴木」と「鈴木 理香」は検索されません。 |
指定した単語に完全に一致する単語 | =
| "=小田"と入力すると、「小田」は検索されますが、「小田川」や「小田山」は検索されません。 "=小田=弘"と入力すると、「小田 弘」や「弘 小田」は検索されますが、「小田川 弘二」などは検索されません。 |
日本語のひらがな、カタカナ、漢字を含む文字 (日本語の索引が設定されたフィールドのみ) | 検索する文字 | |
ひらがな/カタカナ、濁点/半濁点/濁点なし、拗音と促音のかな/通常のかな、かなの濁音/濁音なしの繰り返し記号を区別しない日本語の索引が設定されたフィールドのかな文字 | 検索する文字を ~ (ゆるやか記号) に続けて入力します。 | |
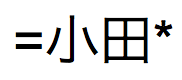 "と入力すると、「
"と入力すると、「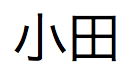 」、「
」、「 」、および「
」、および「 」が検索されます。
」が検索されます。 」と入力すると、「
」と入力すると、「 」、「
」、「 」、および「
」、および「 」が検索されます。
」が検索されます。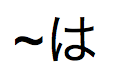 」と入力すると、「
」と入力すると、「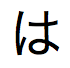 」、「
」、「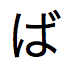 」、「
」、「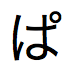 」、「
」、「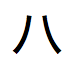 」、「
」、「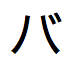 」、および「
」、および「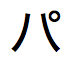 」が検索されます。
」が検索されます。